Augmented Interval List
Nathan Sheffield, PhDLOLA refresher

LOLA requires comparing sets of intervals

Can we improve the efficiency to enable faster, larger-scale analysis?
If subject list has no containment, identifying overlaps is fast

binary search on start intervals, followed by backward steps:

The problem arises with contained interval overlaps


Methods provide non-containment guarantees
R-trees
Annotates tree nodes with a minimum bounding rectangle of elements. A query that does not intersect the bounding rectangle will not intersect any child element.
Nested Containment Lists
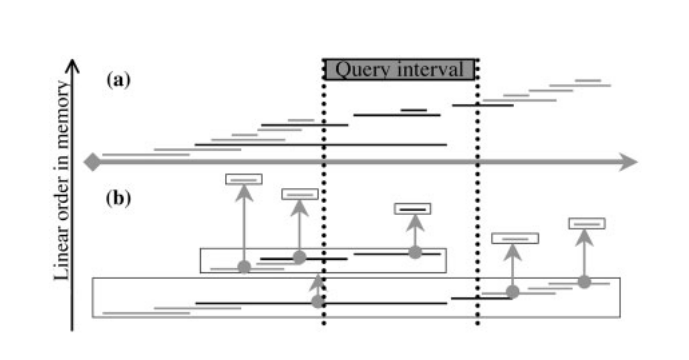
Augment with the running maximum end value, maxE
Provides a local guarantee of no containment.

AIList works on contained lists

But long containment runs are problematic


Decompose long runs with constant maxE

Datasets

How does the maxE minimum run length affect performance?

How does it compare to existing approaches?

How does it scale with increasing size of subject?

Thank You
Sheffield lab
John Lawson
Vince Reuter
Ognen Duzlevski
Jason Smith
Jianglin Feng
Michal Stolarczyk
Aaron Gu
Anant Tewari
Funding:


