Recent advances in genomic interval analysis
Nathan Sheffield, PhDOutline
Augmented Interval Lists
Regionset2vec
|
|
25%
25%
40%
10%
|
|
Integrated Genome Database
BEDbase
◁ Questions ▷
Augmented Interval List (AIList)
A novel data structure for efficiently computing overlapsacross genomic interval data.

Jianglin Feng
If subject list has no containment,
identifying overlaps is fast

binary search on start intervals, followed by backward steps:

The problem arises with contained interval overlaps


How can we improve efficiency
without guaranteeing no containment?
Many approaches to solve the 'containment' issue:
- Nested Containment Lists (GRanges) [@Alekseyenko2007; @Aboyoun2012] - R-trees (bedtools) [@Kent2002; @Quinlan2010], Augmented interval trees [@Cormen2001] These methods try to structure the data to provide non-containment guaranteesMethods provide non-containment guarantees
R-trees
Annotates tree nodes with a minimum bounding rectangle of elements. A query that does not intersect the bounding rectangle will not intersect any child element.Nested Containment Lists
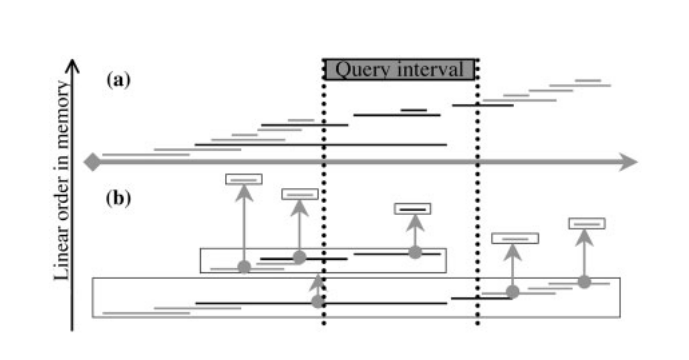
Augmented Interval List
1. Augment the list with the running maximum *end* value. *solves the problem for lowly-contained lists* 2. Decompose the list to minimize containment. *extends the solution to highly-contained lists*Augment with the running maximum end value, `maxE`
Provides a local guarantee of no containment.
AIList works on contained lists

But long containment runs are problematic


Decompose long runs with constant `maxE`

Performance
- How does the `maxE` minimum run length affect performance?
- How does it compare to existing approaches?
- How does it scale with increasing size of subject?
Datasets

How does the `maxE` minimum run length affect performance?

How does it compare to existing approaches?

How does it scale with increasing size of subject?

Conclusion
- Augmented Interval Lists add the maximum running end value to a list of intervals
- The data structure is simpler than other methods
- AILists improve performance, particularly in highly contained interval sets
Integrated Genome Database (IGD)
A high-performance search enginefor large-scale genomic interval datasets.
Jianglin Feng
Expanding the search space


An integrated data structure


GIGGLE
GIGGLE indexes many interval sets with a B+ tree.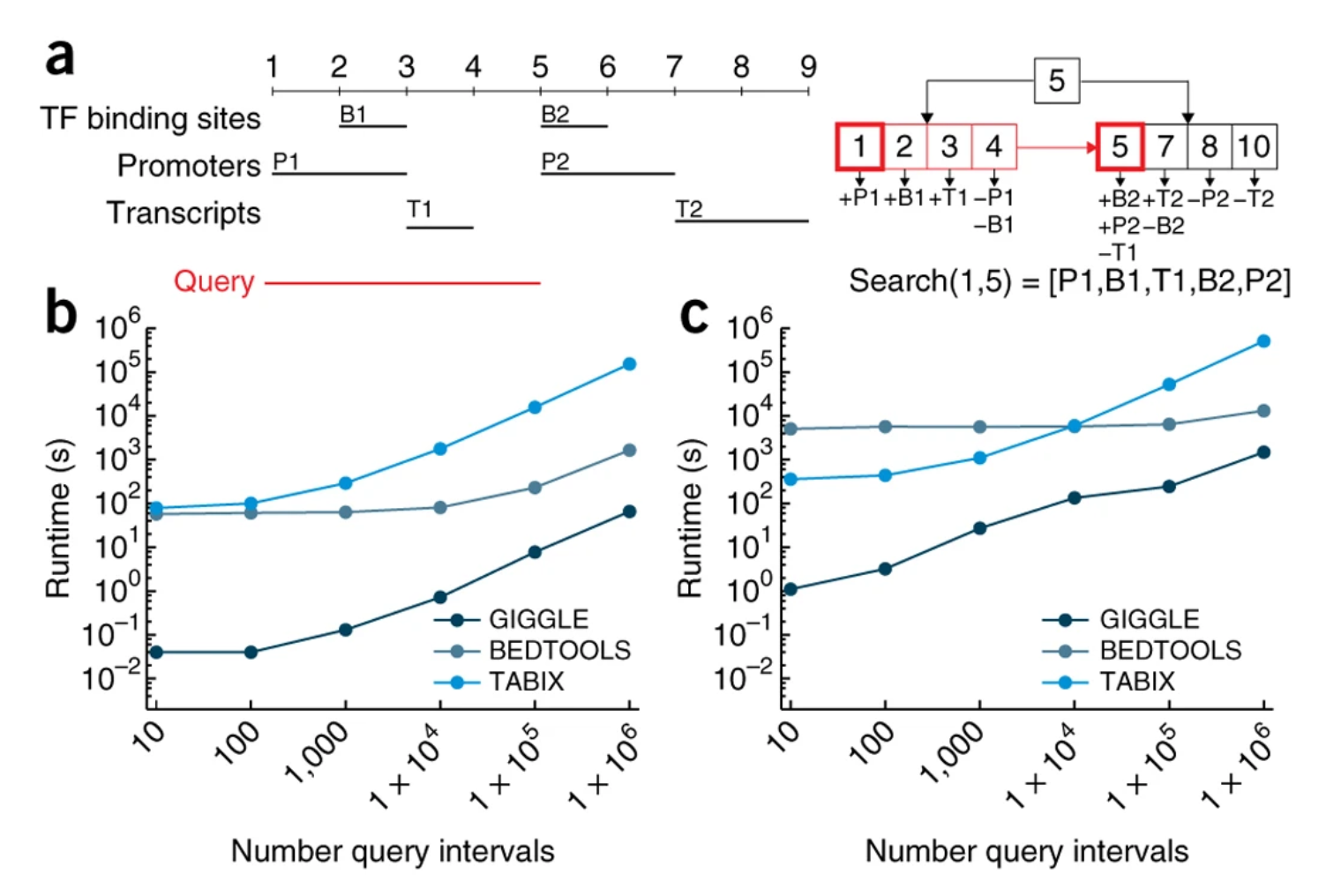
IGD uses linear binning
- The genome is divided into equal-size bins
- Database intervals are placed in any bins they overlap
- Intervals are sorted by start coordinate within a bin

Advantages
- Single-layer data structure has less overhead
- Bins are independent
Challenges
- Duplication = bigger database
- Duplication = possible for double-counting
Challenge 1: Database size
- Adjustable with bin size
- In practice: 5-20% bigger than raw, unduplicated data
- Can be 2x or more if you have smaller bins than regions
- Default bin size: 16,384 (214)
Challenge 2: Double-counting
Occurs only when both query and subject interval cross the same bin boundary. Rule:If the query crosses the left boundary of the bin, then any region in the bin that also crosses the left boundary will be skipped
Question: Within a bin, how are overlaps calculated?
Can we use the AIList search algorithm?
Yes, but it doesn't help much because the bin size restricts the excess comparisons.
Performance

Conclusion
- IGD computes overlaps between a query and database of indexed interval sets
- IGD uses linear binning to index collections of region sets
- Because bins are independent, IGD uses little memory, and could be parallelized
- IGD reduces database size and increases performance
Region-set 2 Vec
Embeddings of genomic region setsin lower dimensions.

Erfaneh Gharavi
Word embeddings
http://suriyadeepan.github.io
Word2vec model
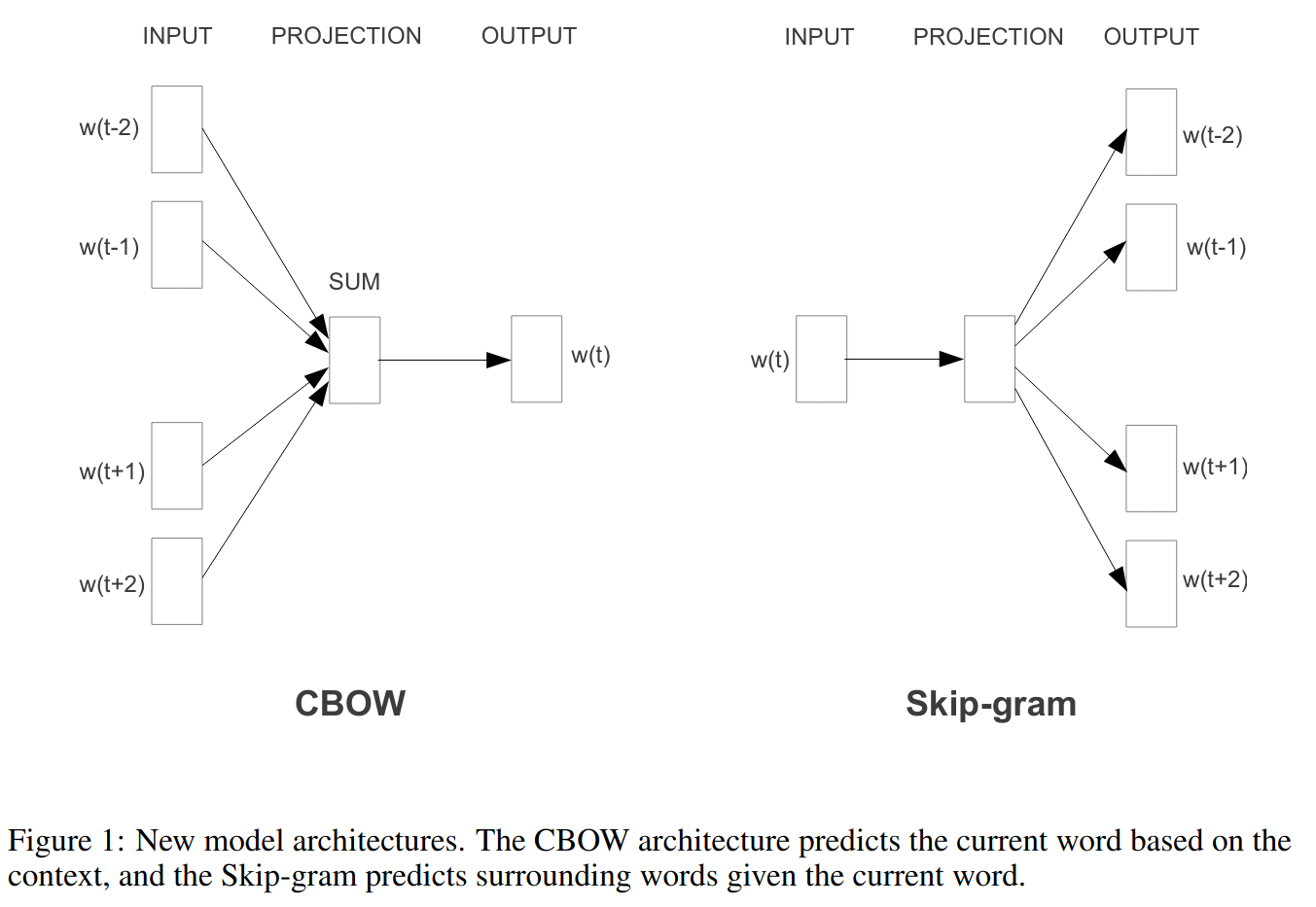
Word context
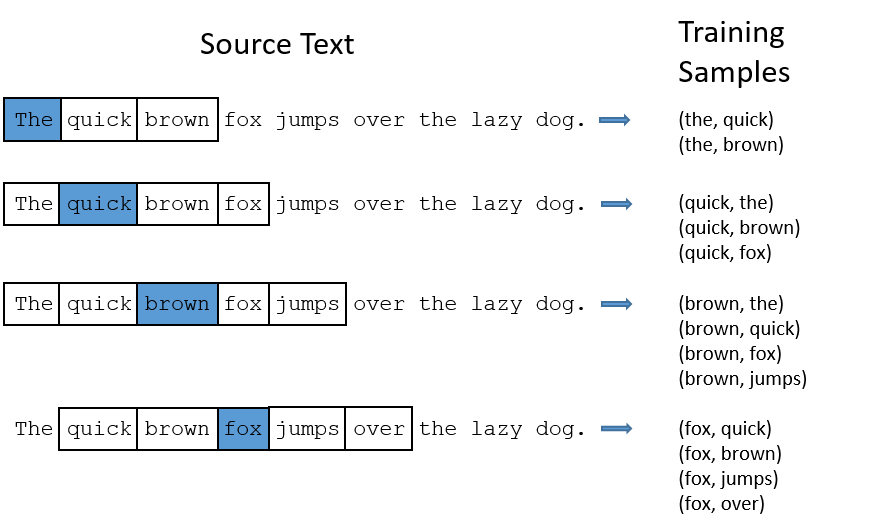
You shall know a word by the company it keeps. (Firth 1957)
Words that occur in similar contexts tend to have similar meanings.
Words that occur in similar contexts tend to have similar meanings.
Image credit: Shubham Agarwal
Genomic context
A genomic interval is more likely to appear in a BED file with other genomic intervals of a similar function.

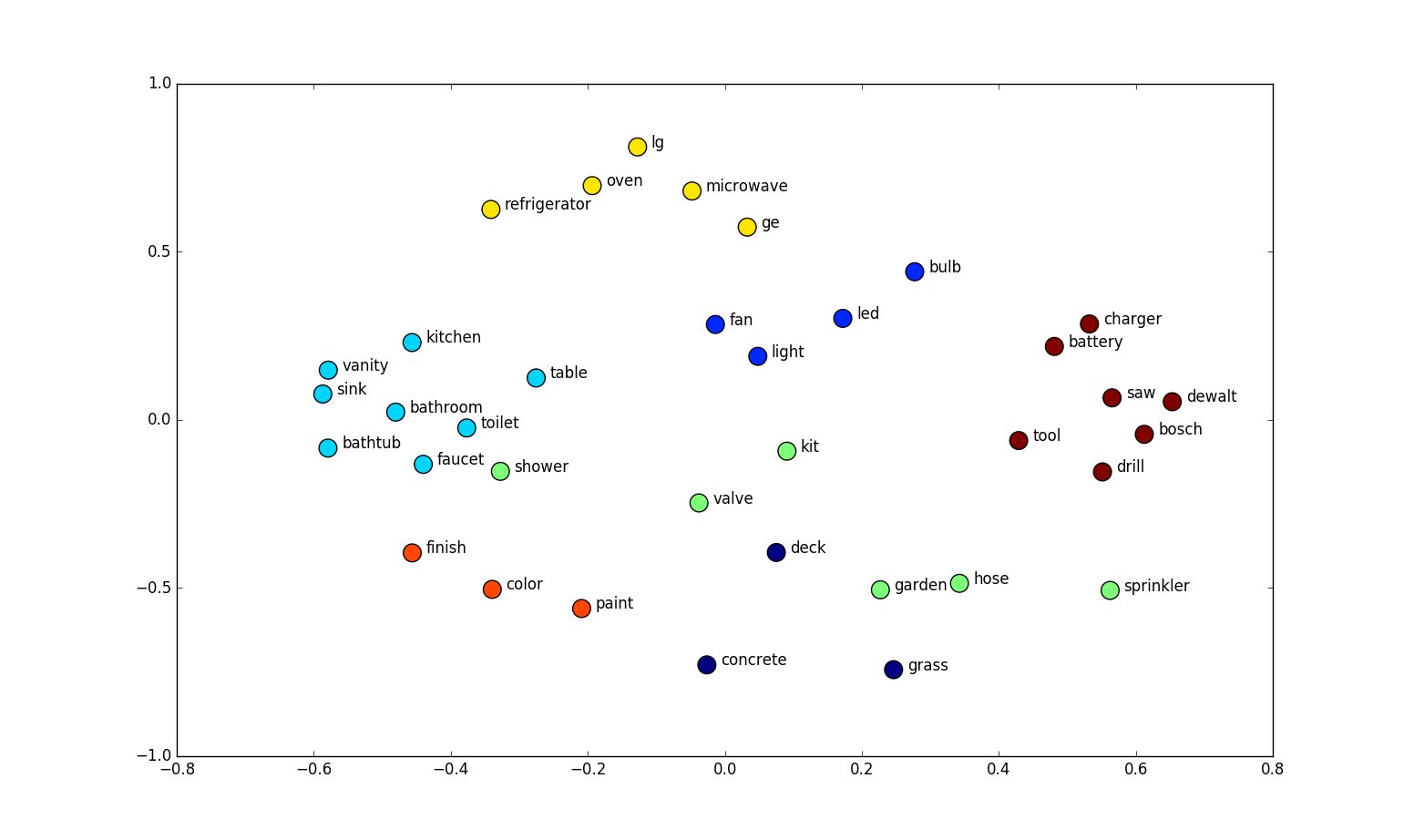
Genomic Interval Embeddings

Evaluation
We have created unsupervised 100-dimensional vector representations (embeddings) of region sets.Do relationships among vectors reflect biology?

Evaluation 1: Classification performance

Evaluation 1: Classification performance

Evaluation 1: Classification performance


Conclusion
- Regionset2vec adapts word2vec to learn genomic region embeddings
- Regionset2vec embeddings capture biological information
- NLP approaches can be adapted for applications in genomic interval analysis

Michal Stolarczyk

Jose Verdezoto

Bingjie Xue

Oleksandr Khoroshevskyi
BEDbase architecture


BEDbase is a microservice for data interoperability,
not another cloud platform
- Web interface (front-end)
- Clients (front-end)
- API (back-end)
- Database and files (back-end/infrastructure)
- Processing pipelines (infrastructure)
- Data served (content)
Human browsing of BED file splash pages
https://bedbase.org/bed/bd2578e70c0efe3674d0d39c782fe9e1Reference genome compatibility


Donald Campbell
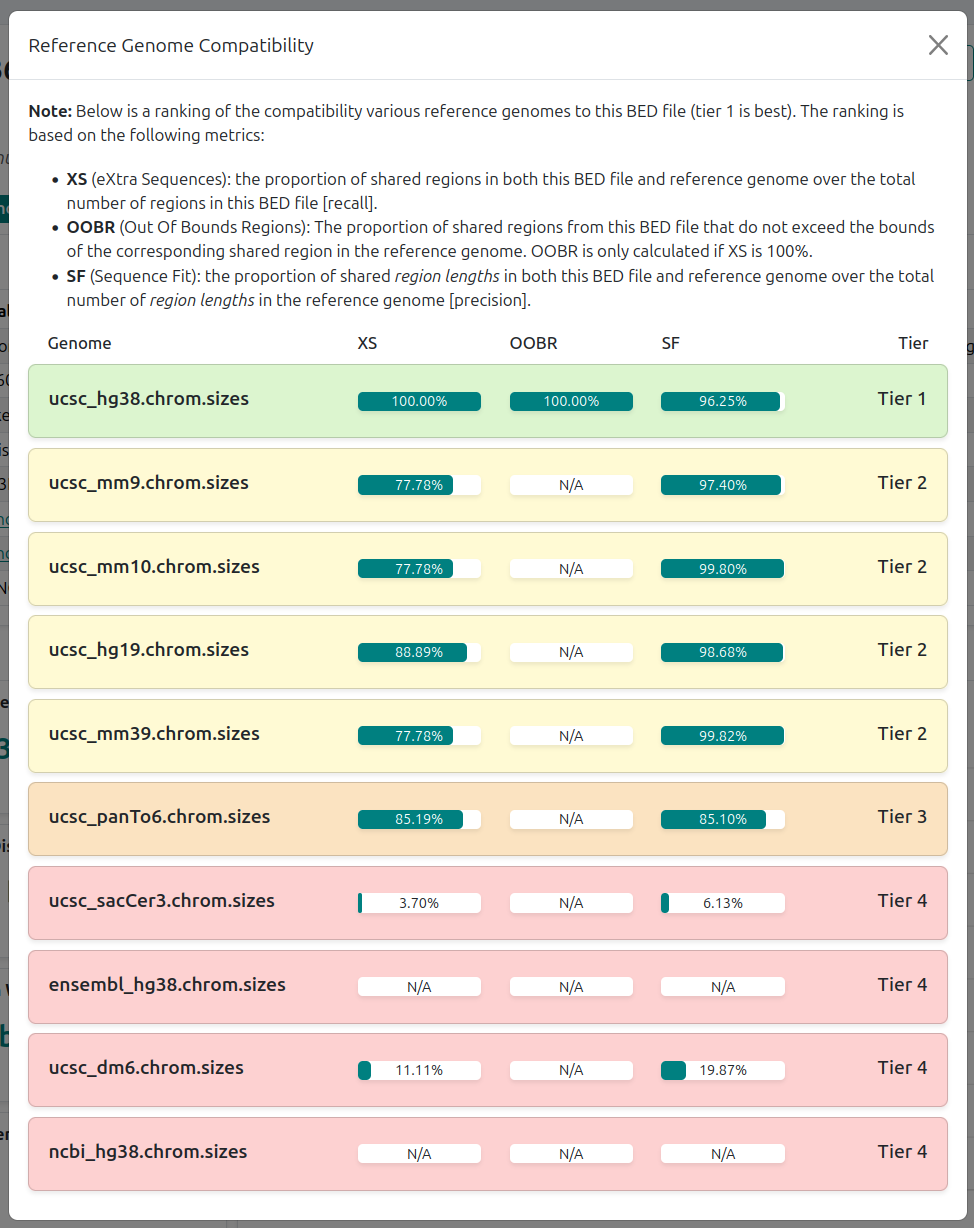
Reference genome compatibility

Donald Campbell
Reference genome compatibility
BEDsets allow comparison of BED files
https://bedbase.org/bedset/gse246900Human-friendly search
Co-embedded metadata and region sets: https://bedbase.org/search?q=brainHuman-friendly search

Human-friendly search

Search by BED file
Co-embedded metadata and region sets: https://bedbase.org/search?view=b2b- Web interface (front-end)
- Clients (front-end)
- API (back-end)
- Database and files (back-end/infrastructure)
- Processing pipelines (infrastructure)
- Data served (content)
BEDbase R client
BEDbase Python client
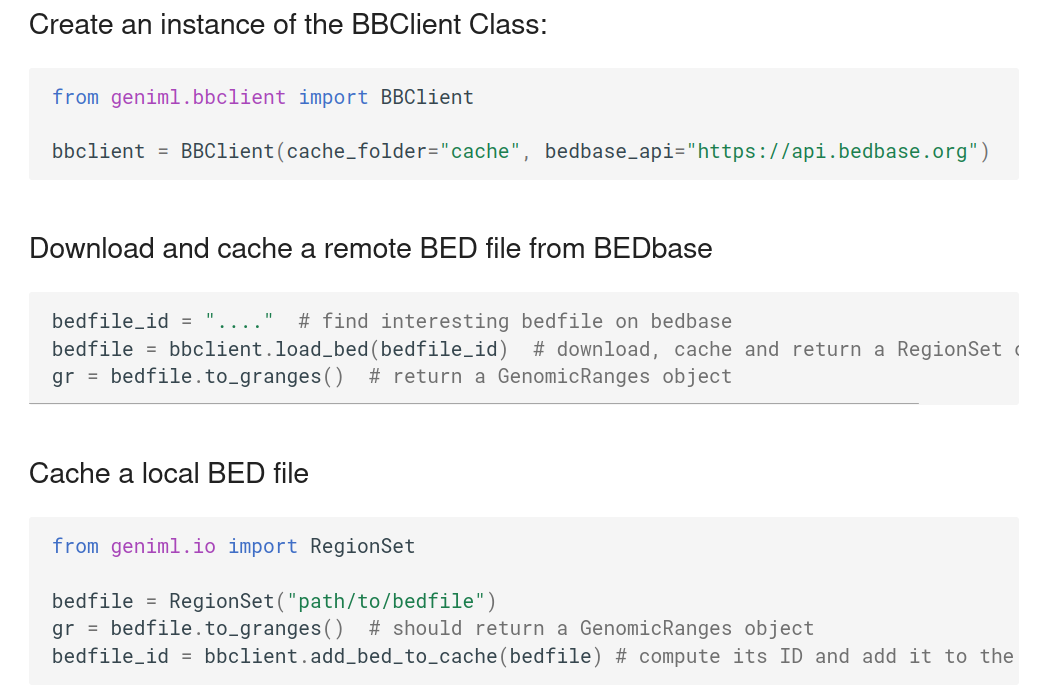
- Web interface (front-end)
- Clients (front-end)
- API (back-end)
- Database and files (back-end/infrastructure)
- Processing pipelines (infrastructure)
- Data served (content)
bedhost
A FastAPI application following JAMstack philosophy. JAMstack forces you to build a comprehensive API.
JAMstack forces you to build a comprehensive API.
OpenAPI interface
https://api.bedbase.org/v1/docsBED info via API
https://api.bedbase.org/v1/bed/bd2578e70c0efe3674d0d39c782fe9e1/metadata?full=true- Web interface (front-end)
- Clients (front-end)
- API (back-end)
- Database and files (back-end/infrastructure)
- Processing pipelines (infrastructure)
- Data served (content)
- Web interface (front-end)
- Clients (front-end)
- API (back-end)
- Database and files (back-end/infrastructure)
- Processing pipelines (infrastructure)
- Data served (content)
Docs: http://code.databio.org/GenomicDistributions/
Code: http://github.com/databio/GenomicDistributions/

Kristyna Kupkova
Jose Verdezoto
Code: http://github.com/databio/GenomicDistributions/
Kristyna Kupkova
Jose Verdezoto

- Web interface (front-end)
- Clients (front-end)
- API (back-end)
- Database and files (back-end/infrastructure)
- Processing pipelines (infrastructure)
- Data served (content)
Connects the Gene Expression Omnibus (GEO)
and Sequence Read Archive (SRA)
with PEP format
Oleksandr Khoroshevskyi
Conclusion
- BEDbase provides BED data for humans and machines
- Output includes statistical and biological visualization
- Upcoming human-friendly search is powerful
- Programmatic access to data chunks improve interoperability
Thank You
Collaborators
Aakrosh Ratan
Aidong Zhang
Guangtao Zheng
Don Brown
Hyun Jae Cho
Vince Carey
Mikhail Dozmorov
Alumni
Aaron Gu
Jianglin Feng
Ognen Duzlevski
Tessa Danehy
Aakrosh Ratan
Aidong Zhang
Guangtao Zheng
Don Brown
Hyun Jae Cho
Vince Carey
Mikhail Dozmorov
Alumni
Aaron Gu
Jianglin Feng
Ognen Duzlevski
Tessa Danehy
Sheffield lab
Erfaneh Gharavi
Michal Stolarczyk
John Lawson
Jason Smith
Kristyna Kupkova
John Stubbs
Bingjie Xue
Jose Verdezoto
Nathan LeRoy
Oleksandr Khoroshevskyi
Erfaneh Gharavi
Michal Stolarczyk
John Lawson
Jason Smith
Kristyna Kupkova
John Stubbs
Bingjie Xue
Jose Verdezoto
Nathan LeRoy
Oleksandr Khoroshevskyi
Funding:



NIGMS R35-GM128636
NIGMS R35-GM128636